We use Resi for our Sunday service stream. The past three Sundays we have had issues streaming our 2nd service. Resi support is pointing the finger at our ISP. Has anyone else experienced recent issues with Resi? We have a report from another local church near us having issues as well.
I am aware of ongoing issues, going back a little further than 3 weeks, at churches in Metro Atlanta and Metro Indianapolis on 3 discrete ISPs.
Resi has indicated that the issue is in the ISP in all cases - but other streaming services are working fine, and we have gone to some lengths to ensure that our networks and ISPs are operating healthily.
We believe the problem to be on their side for the above reasons and other testing we have done.
I am still a fan of Resi and hope they can get to the bottom of this shortly. Hopefully some others will chime in with their issues and/or their successes.
We have experienced the same over the same time period. Last week (1/26) it was so bad that it caused out first services streaming to be a complete loss. All three Sundays our second service was constantly full of alerts from Resi about upload performance. I’m confident that we are not having any bandwidth issues, and that our ISP is providing solid routing. Based on what I’ve heard from others experiencing the same, I believe that there is something going wrong at Resi on the back end and support isn’t aware of it.
Chris, what you described sounds like our experience too. We get through first service and at some point during second service we start seeing alerts and the stream declines until we lose the stream altogether. Last Sunday we switched to our backup ISP (Spectrum) and that didn’t help either! We even had a Resi support rep monitoring our encoder while the issue was happening and they still said it was the ISP.
I’m aware of at least 4 DFW area churches with issues the past 2 weeks at least. 3 different ISPs. We’re also confident this is a Resi platform issue and continue to encourage them to dig deeper on their side.
Just an update - Paul Martel of Resi replied in our Discord Server the following:
Hey all, on behalf of Resi, thanks for bringing this up. We are escalating immediately and will have a resolution or update ASAP (certainly before the weekend). Sorry for the trouble and we are jumping on it to figure out what’s going on with these reports. ISP or not, we are in this together!
1 Like
Hey All,
Thanks to those who were able to provide information about the issues experienced.
The Resi team has done a deep dive and our working theory based on the evidence is that some ISPs (Spectrum, possibly also Frontier and AT&T) have recently (within the last 3-4 weeks) changed the way they route traffic to third party ANYCAST DNS servers. Now, customers with local networks which are configured to use ANYCAST DNS servers may randomly (based on the ISP’s BGP routes) have their DNS requests routed to DNS servers in another part of the country. This causes the encoder to upload content to that same part of the country. For example, a customer in Florida could get sent to a DNS server in California, and the encoder will upload to a datacenter in California - resulting in the video being sent a much farther distance over the internet, which means more routes/handoffs, and much more possibilities for congestion.
We believe there are two independent solutions to the problem:
- Resi does not recommend the use of ANYCAST DNS for streaming. If your network has been configured to use an ANYCAST DNS address (such as 8.8.8.8), you should change the DNS configuration to use non-ANYCAST addresses recommended by your ISP.
- To mitigate this problem even further, Resi is introducing a new alternate / secondary ingest URL for encoder traffic which will automatically be used in the case of issues with related to the use of ANYCAST DNS addresses on encoders. This new ingest URL is expected to be available via an encoder update as early as next week. Updates are managed by the Resi team, so no action on your part for this one.
If you have confirmed that you are using non-anycast DNS addresses and are still experiencing issues, please submit a support ticket to support@resi.io and we will deep dive with you!
Also, I consider myself a guest in this channel and do not want to dominate conversation. As always, please feel welcome to disagree or continue conversation as you need, but I (and we at Resi) did want to try to help based on what we saw here.
Related post by the famous Jason Lee
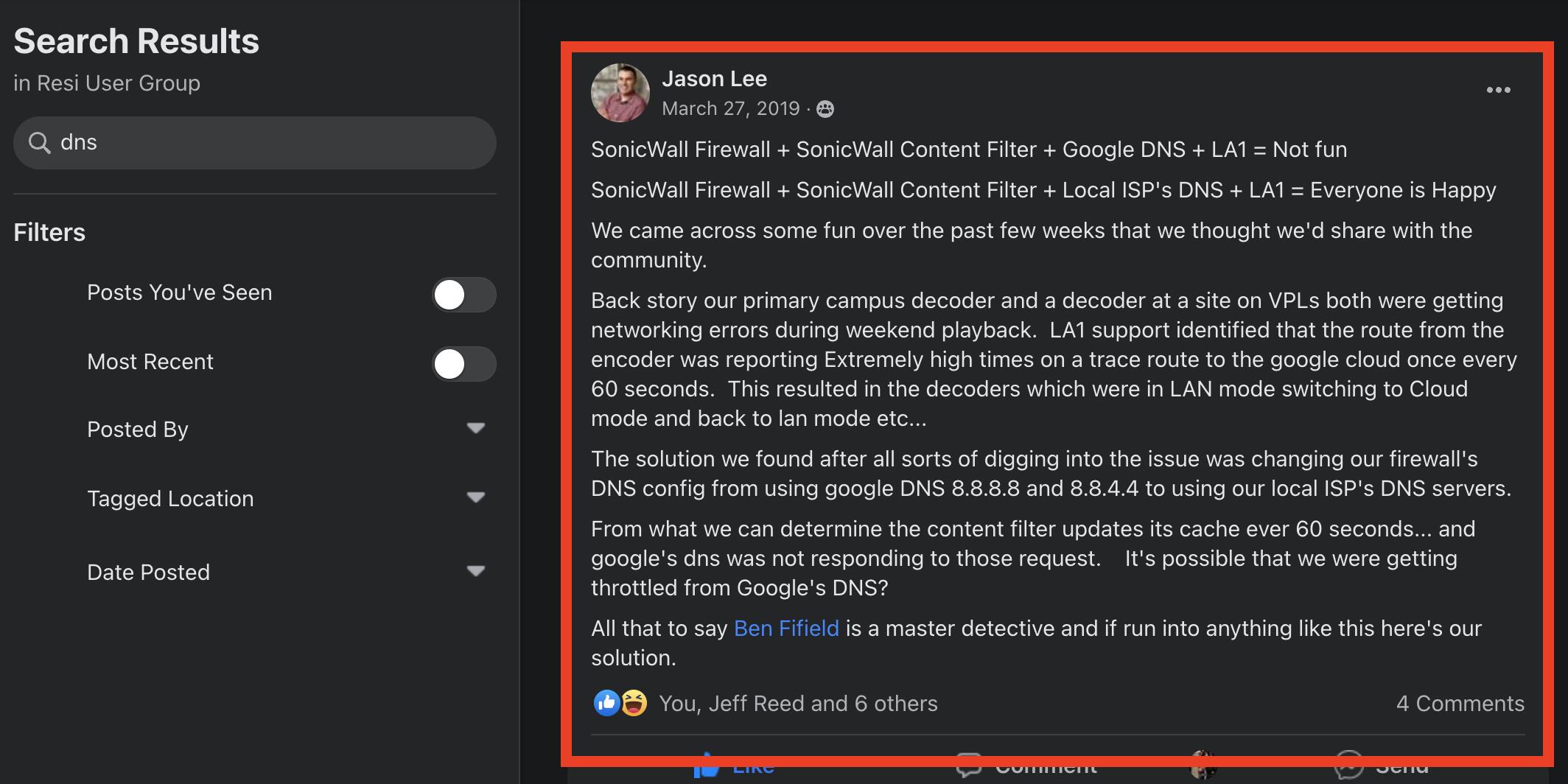
Thanks for that update @Paul_Martel! Our standard across all clients is to utilize Cloudflare DNS (yes, it’s an ANYCAST setup). Am I correct in assuming that if we set a static DNS config on the Resi encoders and decoders this would be sufficient? We have all sorts of issues with ISP-provided DNS for our general usage. But I could certainly see value in not using ANYCAST for the Resi gear based on your comments.
Just to save me looking: Can we set static DNS on the Resi gear without setting a static IP? Or would we need to do full static IP config in order to specify static DNS?
It’s still early, but we appear to have strong evidence suggesting that the use of at-least the Cloudflare DNS anycast address of 1.1.1.1 is causing traffic to flap destinations and be routed all over the world (South Africa, Taiwan, Indonesia, etc). Using local ISP DNS addresses, or Google’s 8.8.8.8 do not appear to have the issue. We have a ticket open with Google requesting them to review their BGP routes and Cloudflare to review their anycast addressing service.
Regarding setting a static DNS address on the Resi encoders and decoders, yes, that should work, so long as your firewall or gateway does not block DNS service from client devices. You cannot set a static DNS address on encoders from the web interface without also setting a static IP, but you can from the local GUI. If you need to do this on encoders, please reach out to support@resi.io and they can help.
Cloudflare (1.1.1.1) and Quad-9 (9.9.9.9) DNS don’t support a feature called EDNS Client Subnet, where the resolver is able to forward your IP address information to an upstream DNS. They will generally have worse performance across the board.
Anyone who’s curious about what Cloudflare POP they’re currently being routed to, you can go to https://cloudflare.com/cdn-cgi/trace and look for the like “COLO=.” This is where upstream DNS providers will try and target their response to, not your location.
Reference:
Just for added clarity, we no longer believe that anycast is the problem in this case; it’s related to how Cloudflare DNS is working and the problems it is causing.
Cloudflare’s DNS service appears to be using a global cache for their DNS servers rather than regional caches, and DNS is resolving to different IPs every few seconds. The result is that DNS queries can return the IP address of servers from anywhere in the globe, and those addresses (locations) are changing drastically very quickly from one request to the next.
I’ve attached a sample below:
% dig @1.1.1.1 storage.googleapis.com
; <<>> DiG 9.10.6 <<>> @1.1.1.1 storage.googleapis.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19727
;; flags: qr rd ra; QUERY: 1, ANSWER: 12, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION
;storage.googleapis.com. IN A
;; ANSWER SECTION:
storage.googleapis.com. 193 IN A 142.251.33.16
storage.googleapis.com. 193 IN A 172.217.1.144
storage.googleapis.com. 193 IN A 142.251.32.144
storage.googleapis.com. 193 IN A 142.250.68.144
storage.googleapis.com. 193 IN A 172.217.14.176
storage.googleapis.com. 193 IN A 142.250.138.128
storage.googleapis.com. 193 IN A 142.251.46.144
storage.googleapis.com. 193 IN A 142.251.40.80
storage.googleapis.com. 193 IN A 142.250.68.176
storage.googleapis.com. 193 IN A 142.251.116.128
storage.googleapis.com. 193 IN A 142.251.32.208
storage.googleapis.com. 193 IN A 142.251.32.240
;; Query time: 12 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Fri Jul 08 14:43:43 CDT 2022
% dig @1.1.1.1 storage.googleapis.com
; <<>> DiG 9.10.6 <<>> @1.1.1.1 storage.googleapis.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 39788
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;storage.googleapis.com. IN A
;; ANSWER SECTION:
storage.googleapis.com. 183 IN A 142.251.36.144
storage.googleapis.com. 183 IN A 142.251.37.112
storage.googleapis.com. 183 IN A 142.251.36.112
storage.googleapis.com. 183 IN A 142.251.36.80
;; Query time: 24 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Fri Jul 08 14:43:45 CDT 2022
;; MSG SIZE rcvd: 115
The requests were made 2 seconds apart from DFW over wifi. They both return very fast - indicating that they are likely hitting a DFW DNS server with results cached, but return totally different destinations. Some in Dallas, some in the Czech Republic, etc. This pattern continues with locations like South America, Taiwan, Indonesia, etc. This means your data is going all over the world very inconsistently when using Cloudflare DNS + nameservers which can resolve to multiple IPs/destinations.
Paul - I presume your team knows that on a service like google, rapidly changing IPs behind a hostname will be standard practice.
Additionally, it’s famously hard to use geolocation to know where those IPs are inside a hyperscaler - things move around a lot - sometimes daily - so unless your opening a session and doing RTT monitoring inside said session, it’s hard to know what’s going on. Your dig results look like what I’d expect - and indeed what they look like from half a dozen ISPs own DNS servers I just tried.
That all said - is it wrong to assume that once the encoder or decoder comes online, it will do a single resolution, open a single (or small set) of sockets and use that throughout the ingest or playout session? Presuming that is true - it shouldn’t matter that the IPs are moving around a lot behind a resolution - even if they are traveling to the other side of the country (or course the other side of the world is less than ideal).
Hey Karl,
Thanks for your feedback over the past few days, and all your great questions! Yes, we are aware that IPs can and will change often on such a service, but the behavior as described is not normal. A DNS server resolving IPs in DFW should not be returning locations across the world when there are local POPs available all over the US. We are not observing other DNS services like quad-8 or even quad-9 return such geographically schizophrenic results.
Yes, I would agree that it is hard to be certain of where any particular IP is physically located. But we were not looking at just one aspect of data. Our encoders do automatically run trace-routes when they detect upload issues. We looked holistically at weeks worth of this data, and through a combination of reported locations for IP addresses, along with naming conventions of namespaces, the latency of sequential hops, etc, we are quite certain about the behavior we observed and described.
The encoder’s behavior works similarly but not quite exactly as you described. RSP can use multiple connections to load balance across multiple paths and multiple first-mile networks simultaneously. This is what enables customers to use multiple cellular hotspots to “increase”/aggregate bandwidth without the complexity of bonding. While connections can be (and are) reused, any connection can be broken at any time; any datacenter could go down at anytime; and a new connection will be made and no content will be lost. This approach maximizes the dynamic resiliency and scalability that the internet and cloud infrastructure provides. Our encoders can handle flapping between POPs within the same continent (lets not push our luck though, ya?), but when you have DNS servers instructing some parts of high bitrate content to be sent to from DFW to South America, and other parts to India – within seconds apart, it causes problems because even multi-regional services were not designed to ingest data like that. That’s what happened here. In seven yaears of running this service we’ve never seen this particular Internet problem cause issues which impacted broadcasters… but if it happens again, we’re going to make sure that Resi streams won’t be impacted.
I work with Tim @tinkx2. This Sunday’s stream was great for both services. Based off Resi’s recommendation we changed the DNS on just the encoders to use our ISP’s DNS. Before this Sunday they had been set to our local DNS server which had 1.1.1.1 as the primary. After all this, I have lost some confidence in Cloudflare public dns so have bumped 1.1.1.1 down to the secondary and 8.8.8.8 is primary again on our local dns. I had moved Cloudflare to the primary several months back, mainly because we use Cloudflare is the dns host for most of our many websites.
@Paul_Martel thank you to you and your team for figuring this out. It was so nice to have a buffer free Sunday.
1 Like
Yeah; it’s important to note 1.1.1.1 is a privacy focused DNS service. It’s not necessarily targeting performance. Same with 9.9.9.9. I’d also not recommend mixing and matching DNS solutions as that can cause some really hard to chase down issues – especially when clients start resolving on the secondary server occasionally. It’s usually pretty obvious when one of the major DNS providers are down and you can just swap out the name servers then.
1 Like
We had issues on Easter of all Sundays. Resi tried to blame our internet, but the internet never actually went down. I pressed on Resi support harder and they think it was because our encoder was running old firmware. They updated the firmware and so far we haven’t had any issues.
For the last two weeks, we are experience similar Resi bandwidth issues on two of our campuses in the Las Vegas area. We are on Cox business fiber and we are experiencing the same stream drop on the encoders and decoders that are on two separate campuses. We have checked our traffic from the front end of the SD-WAN as well as all of our internal switches that our production team uses. All of the equipment came back with no dropped packets or slower than upload speed. But yet we still have our Resi streams completely drop as if the whole VLAN dropped out. Our Production team called Resi to work on this issue, but they are insisting that it’s our ISP’s issue.